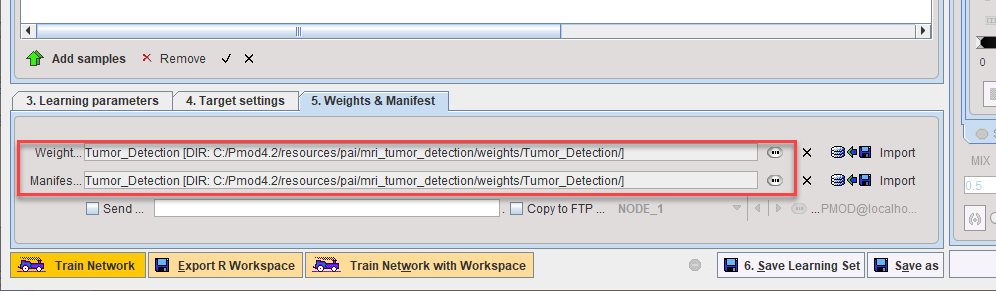
Training of the neural network can be performed in three different ways represented by the three buttons at the bottom of the dialog window:
![]()
1.The Train Network button directly starts the configured training locally. Depending on the checkbox Use GPU, either your CPU or GPU will be used. Note that only the samples selected in the 3. Samples list will be used for the training. As a result, the weights and manifest files will be updated.
2.When activating Export R workspace, the configured preprocessing operations are applied to the selected data and the resulting images are exported together with the training configuration in the form of a compact R workspace. The workspace can then be transferred to a more powerful processing environment for the actual training. This can either be another PMOD installation on a more powerful machine or in the cloud.
3.The Train Network with Workspace button opens a dialog window for loading a previously exported R workspace and starts the training locally.
Deployment
After completion of the training, the resulting Weights and Manifest files can be transferred, along with the definition of the model if necessary, to other PMOD installations for prediction.
Recommendations
On typical personal computers local training is only recommended for tests with a limited amount of data. Performance may be acceptable with data that has a small matrix size (e.g. 50 x 50 x 50 for cropped PET data) and low number of input series for multichannel segmentation (e.g. 1 or 2). The total time required for training cannot be estimated. While training is running you will see a significant load on CPU/GPU. Even for powerful workstations, training with hundreds of samples may take many hours. Training on a cloud computing infrastructure with virtual machines accessing several GPUs is likely to be more time- and cost-efficient.
It is advisable to always perform a small "infrastructure check" training before launching training with your full data set and many epochs. This can be performed using the minimum requirement for input samples (2 samples), a batch size of 1 and a low number of epochs (1 is acceptable, but 2 or 3 will reveal changes in the loss value in the Manifest). If the input data has a high matrix size (e.g. 200 x 200 x 200) and/or there are multiple input series in the sample, the data volume could be reduced by using a larger pixel size for this training test (e.g. 2 x 2 x 2 mm instead of planned 1 x 1 x 1 mm).
Training Progress and Output
For data prepared on your local system, training is started by selecting the desired samples in the Learning Set and clicking Train Network:

The RConsole opens and the Execution test and PAI diagnostics test are performed. If the tests are passed the selected samples (all input series and associated Segments) are loaded:
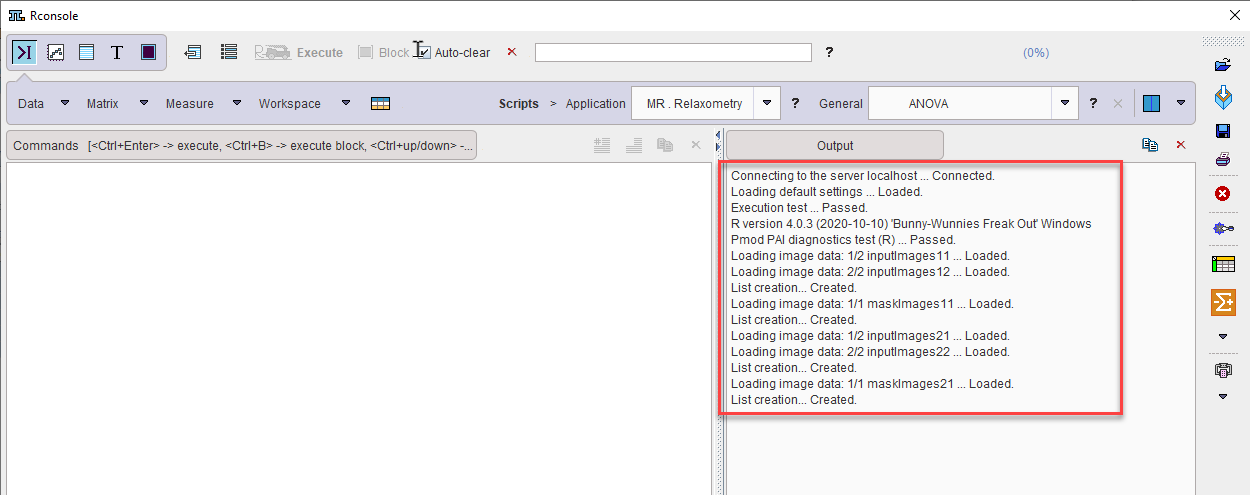
During training a high CPU/GPU load can be observed in the system monitor (Windows 10 Task Manager shown):
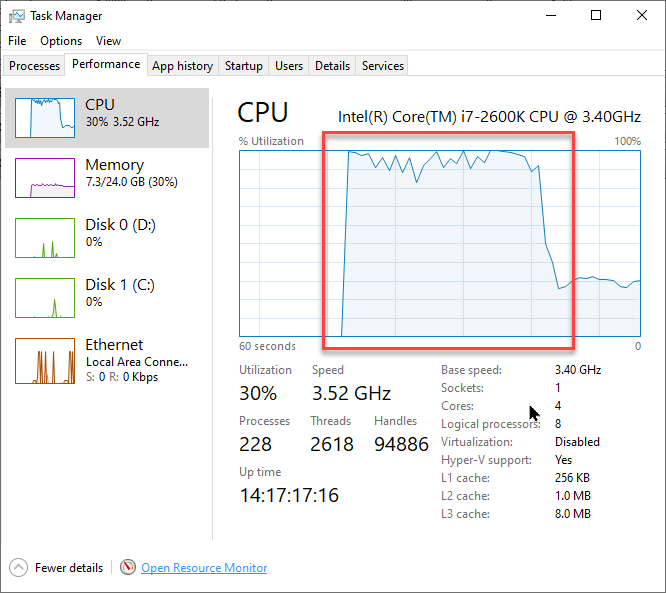
Once training is complete a dialog appears to save the Weights. They can be saved to the database or file system (the same database as the Learning Set is recommended):
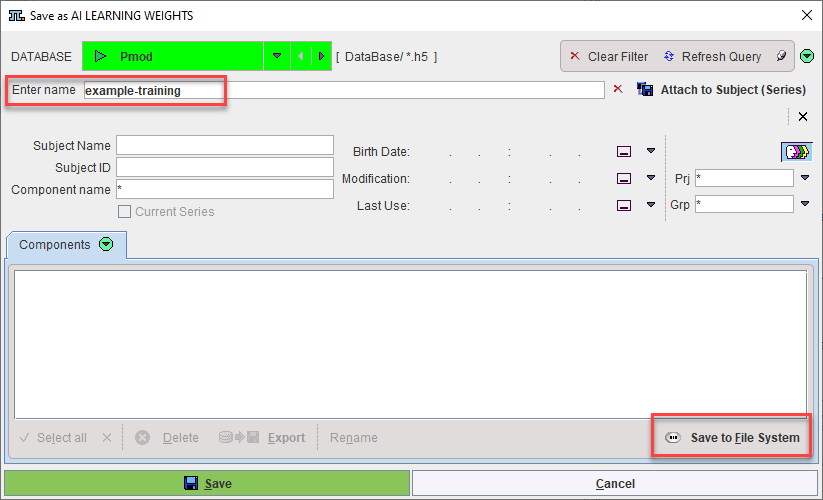
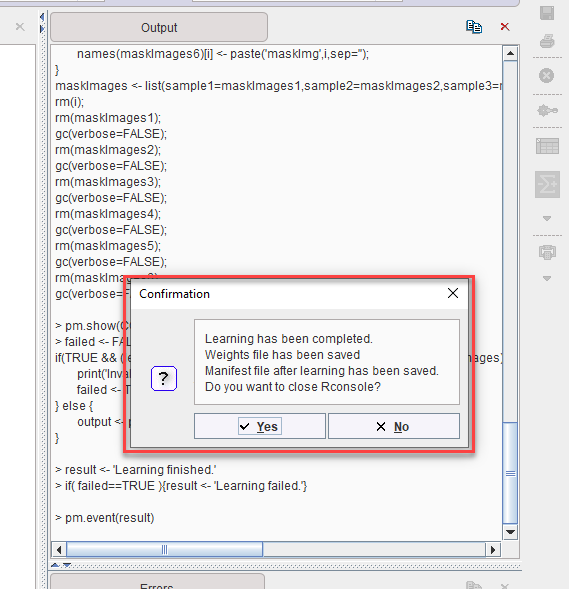
A confirmation dialog in the RConsole confirms that learning was completed and the components saved. The RConsole can be closed:
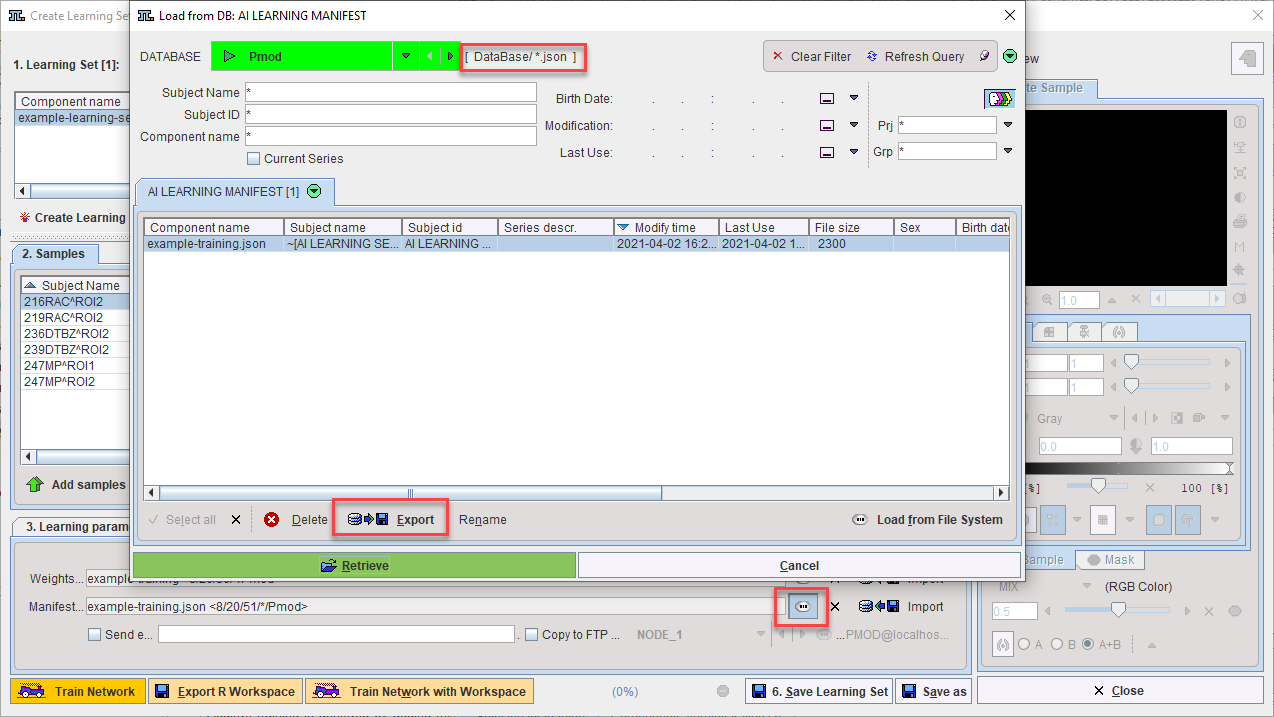
The Weights and Manifest are now attached to the Learning Set:

Details of the training are recorded in the Manifest. It can be exported and read using a text editor:
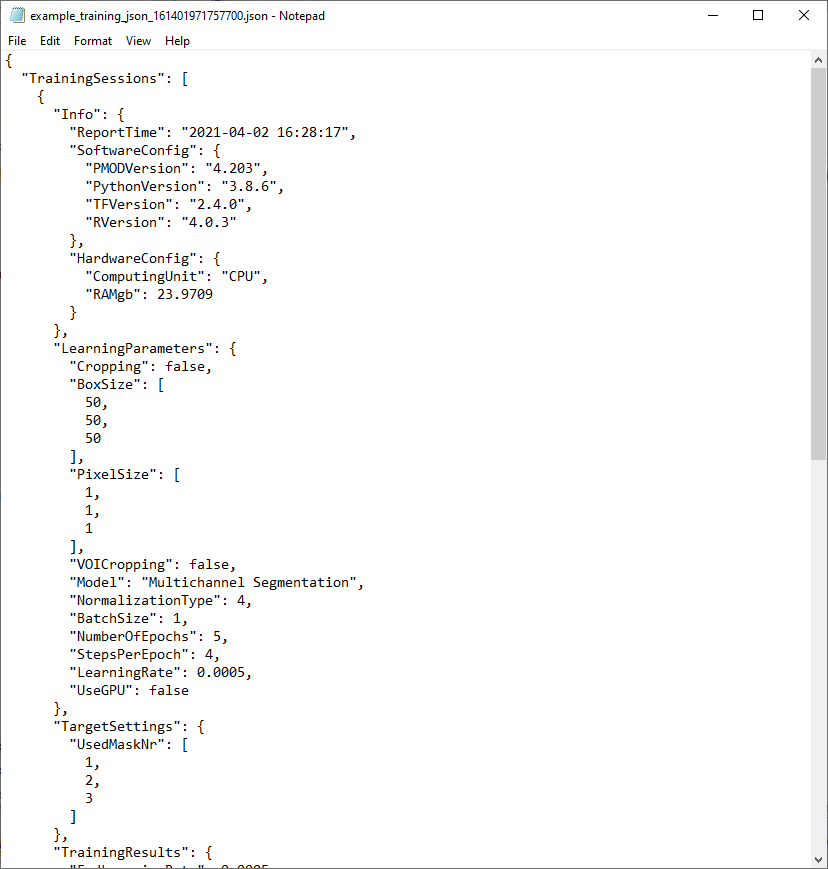
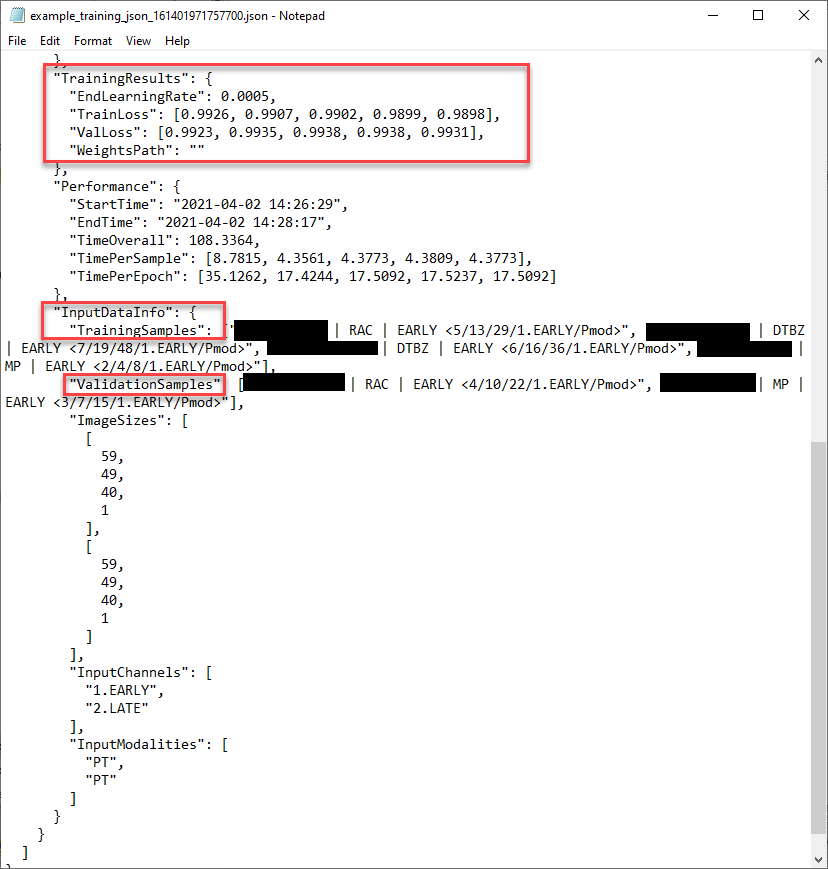
The content of the Manifest file is as follows. The evolution of the training loss value with each epoch can be observed, and those samples used for training and for validation can be identified:
Additive Training
The best results are achieved by training in a single session with the maximum amount of data available. However, in a situation where the initial number of samples is limited and new samples will become available on a regular basis it is possible to try additive training. For example, where 50 samples are available at the start of a project and 10 new samples will be preprocessed every two weeks.
Additive training is achieved by adding the new samples to your existing Learning Set, selecting a subset of the total Learning Set (a combination of existing samples and new samples is recommended, e.g. select the 10 new samples and 10 existing samples), then launching Train Network based on the existing Weight and Manifest (identified on 5. Weights & Manifest).